Benchmarks¶

Benchmarks is a tool to monitor and log reinforcement learning experiments. You build/find any compatible agent (only need an act method), you build/find a gym environment, and benchmarks will make them interact together ! Benchmarks also contains both tensorboard and weights&biases integrations for a beautiful and sharable experiment tracking ! Also, Benchmarks is cross platform compatible ! That’s why no agents are built-in benchmarks itself.
You can build and run your own Agent in a clear and sharable manner !
import benchmarks as rl
import gym
class MyAgent(rl.Agent):
def act(self, observation, greedy=False):
""" How the Agent act given an observation """
...
return action
def learn(self):
""" How the Agent learns from his experiences """
...
return logs
def remember(self, observation, action, reward, done, next_observation=None, info={}, **param):
""" How the Agent will remember experiences """
...
env = gym.make('FrozenLake-v0', is_slippery=True) # This could be any gym-like Environment !
agent = MyAgent(env.observation_space, env.action_space)
pg = rl.Playground(env, agent)
pg.fit(2000, verbose=1)
Note that ‘learn’ and ‘remember’ are optional, so this framework can also be used for baselines !
You can logs any custom metrics that your Agent/Env gives you and even chose how to aggregate them through different timescales. See the metric codes for more details.
metrics=[
('reward~env-rwd', {'steps': 'sum', 'episode': 'sum'}),
('handled_reward~reward', {'steps': 'sum', 'episode': 'sum'}),
'value_loss~vloss',
'actor_loss~aloss',
'exploration~exp'
]
pg.fit(2000, verbose=1, metrics=metrics)
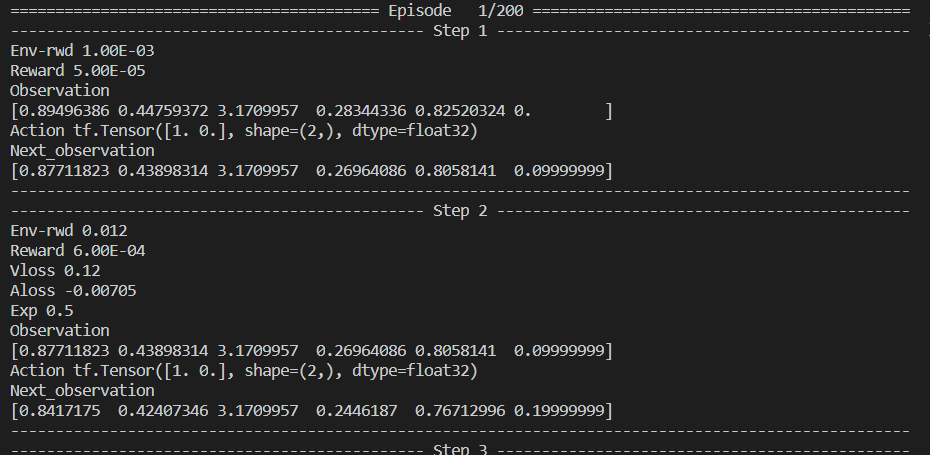
The Playground will allow you to have clean logs adapted to your will with the verbose parameter:
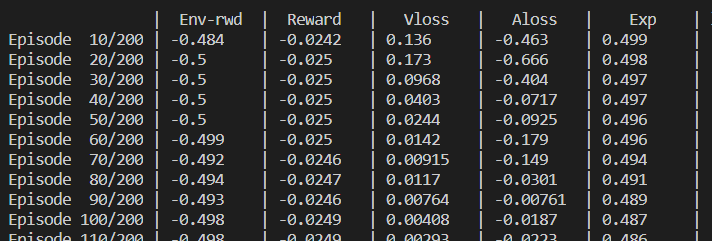
- Verbose 1episodes cycles - If your environment makes a lot of quick episodes.
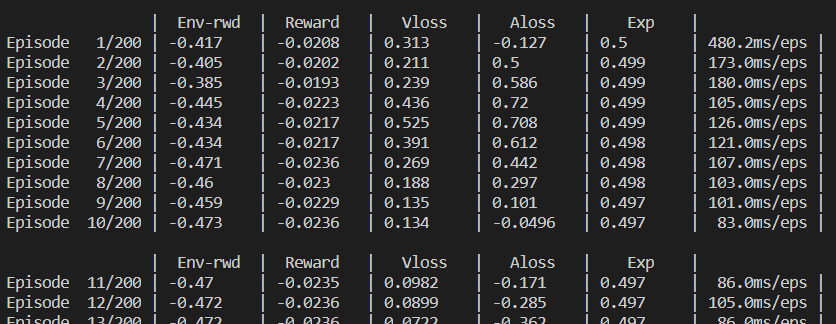
- Verbose 2episode - To log each individual episode.
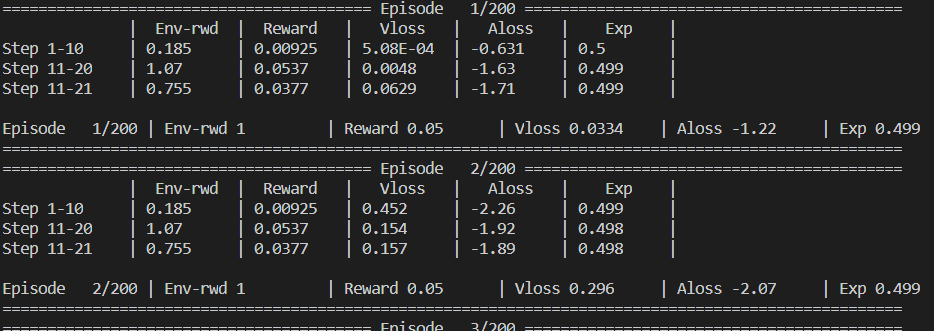
- Verbose 3steps cycles - If your environment makes a lot of quick steps but has long episodes.
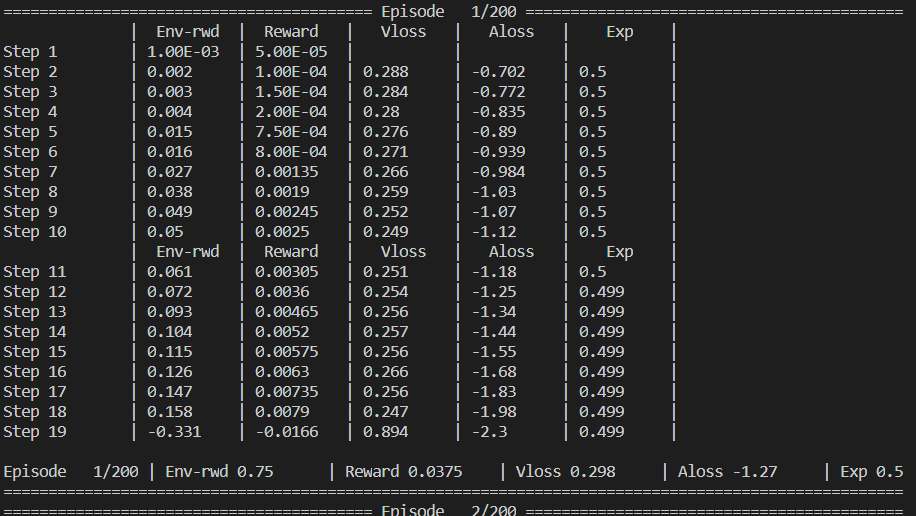
- Verbose 4step - To log each individual step.
- Verbose 5detailled step - To debug each individual step (with observations, actions, …).
The Playground also allows you to add Callbacks with ease, for example the WandbCallback to have a nice experiment tracking dashboard using weights&biases!
Installation¶
Install Benchmarks by running:
pip install benchmarks
Documentation¶
Contribute¶
Support¶
If you are having issues, please contact us on Discord.